In loving memory of Professor Jim Fallon, UCI––Science Advisor to Aiki Wiki 2007-2023
March 23, 2024
Terms for piloting Aiki Wiki testing.
Pilot conversations require a commitment to participate in a critical conversation.
Please reach out to Rome at bigmotherdao dot com if you are interested in participating a closed pilot.
We have successfully demonstrated conversation threshold into publishing permissions through our computational system for single one on one conversations around a single consensus point.
Closed Pilot: Computational Conversation
In our pilot, we demonstrate a computational system for natural human conversation that can allow for any possible emergence (conflict, brainstorming, etc) to reach a threshold for consensus publishing which is otherwise immutable in the system unless there is collaboration.
Allowing for this are nine “narrative events” that a conversation can possibly pass through. For our pilot, we are deploying a customizable narrative theme around Tennis, using Tennis terminology to reflect different arcs.
“Consensus publishing” is a mechanism design that only produces “win-win consensus editing” as the dominant strategy of the system. This allows for novel incentives for decision making by composing a document.
Depending on the flow of the conversation, participants are moved further away from or closer to consensus influence via editing permissions to change the system.
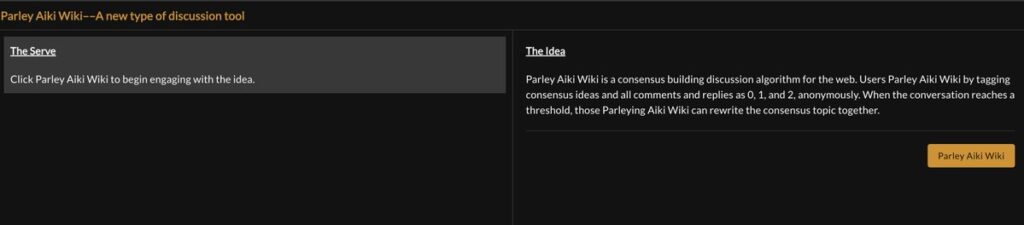
The Serve
The first chapter of game play is simply the discovery of an idea topic that is “served” to the individual, where they can choose to Parley the idea.
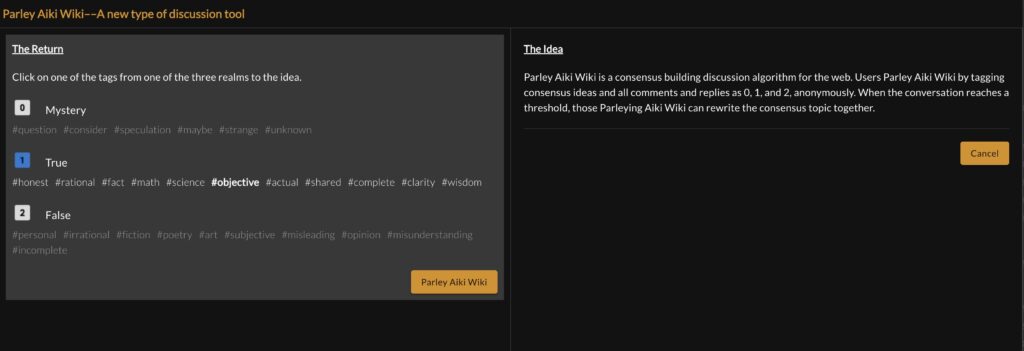
The Return
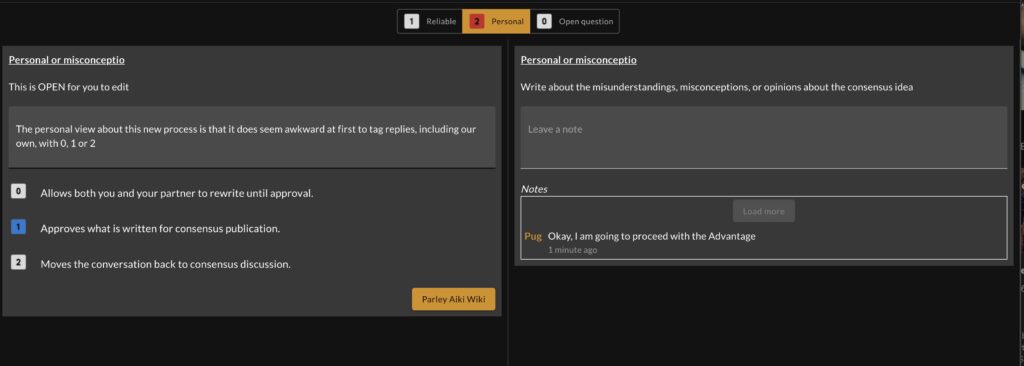
Once Parley is initiated, the user can “return the serve”, first by tagging the idea 0, 1 or 2 and adjusting the tag if necessary…here the default #tag for 1 was adjusted to #objective.
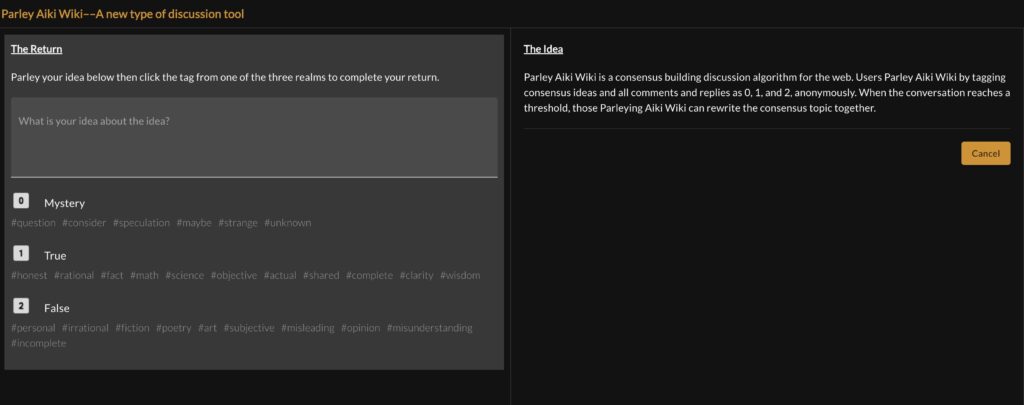
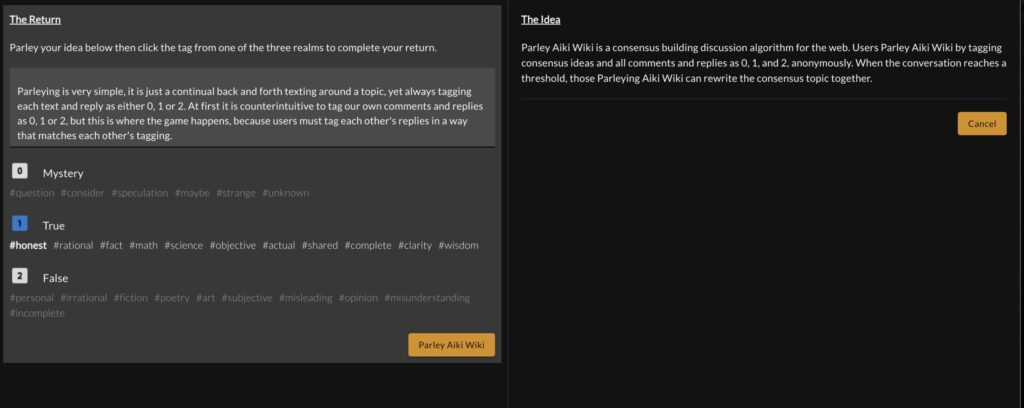
Once tagged, the user completes “The Return” on “The Serve” by leaving their own idea or reply to the topic, and then tagging their own reply with 0, 1, or 2.
This is really all there is to Parley Aiki Wiki, tagging other’s ideas, comments or replies, replying with our own ideas or comments, and then also tagging our own reply with 0, 1 or 2.
Love
Next, the person replying is “matched” with another participant in “Love”, the third component of Parley Aiki Wiki, the part of the game where two anonymous participants are “paired” for the conversation, meet up to collaborate, or combat.
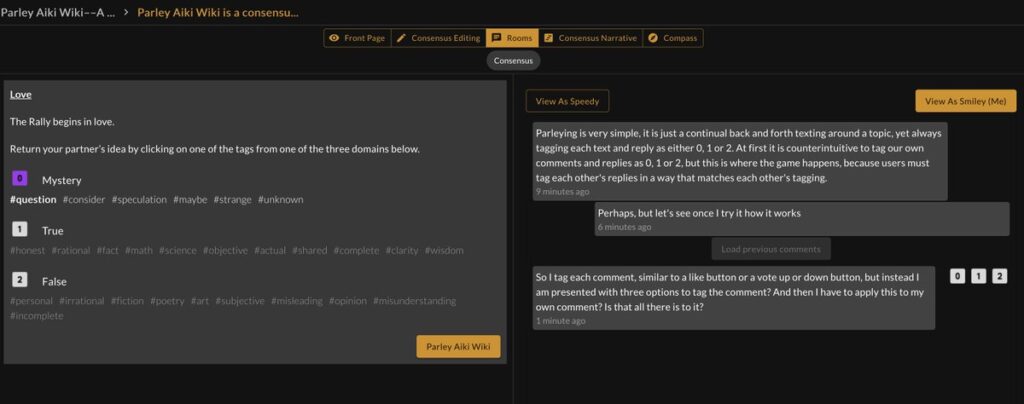
Rally
Once participants are paired, natural conversation can go in any potential direction. This part of game play is called “Rally”, tagging and replying to each other’s responses.
Depending on the participants decisions, the conversation can go in any direction and no matter which direction the conversation goes in, the computational system can mirror and match it.
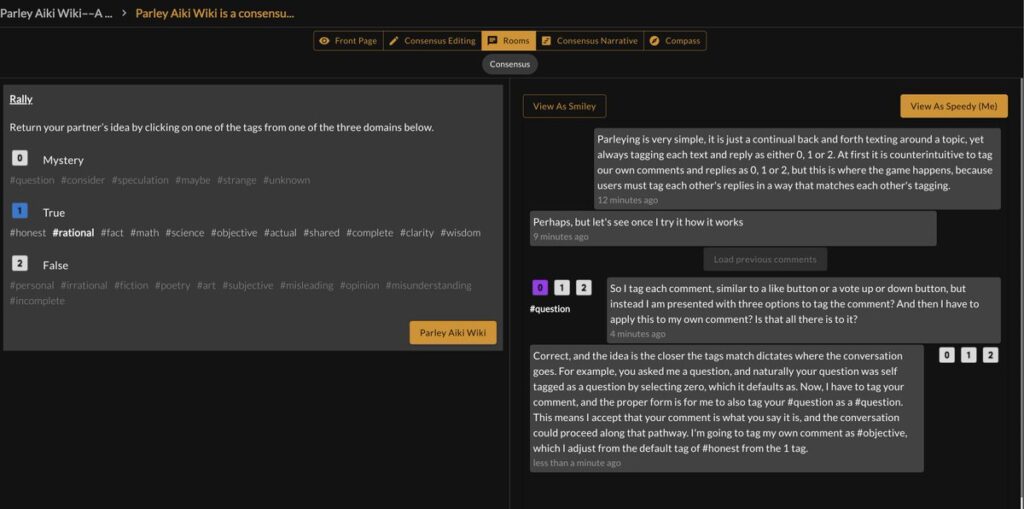
The system can determine if the conversation reaches a threshold which can allow users permission to begin rewriting the consensus idea…together.
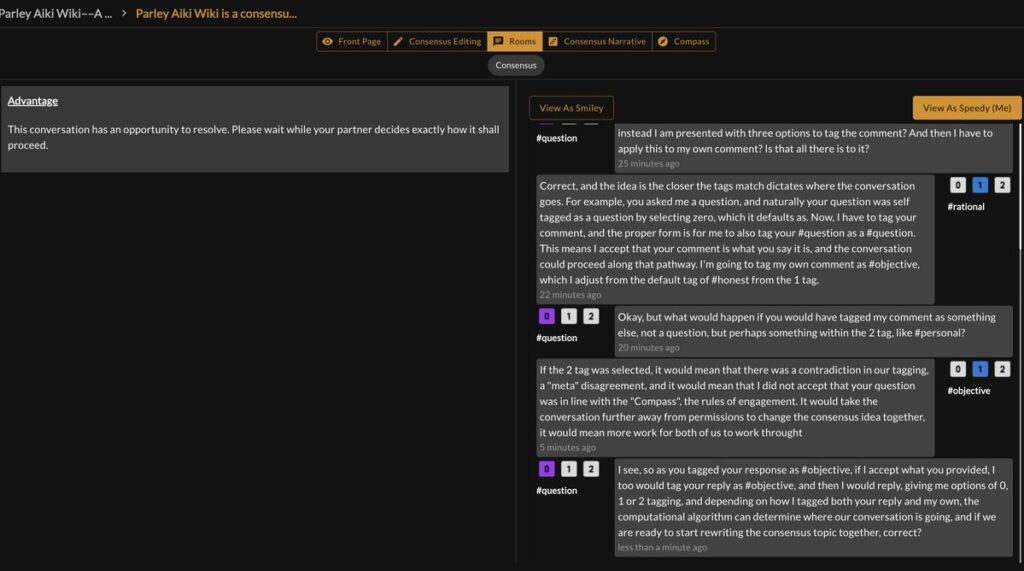
Fault and Spin
But what happens when there is foul play?
What if one anonymous user introduces classic “bullshit” or attempts to bully their way through the process? The tool applies something like game theory to the obtaining of permissions to change the consensus idea, a game of combat and collaboration, where resolution is the only possible outcome. This means that within the game play, the conversation can take turns for the worst, such as manipulation, deception, the promulgation of misleading information, and filter it away from consensus building and even ranking. The system keeps the problematic conversation at bay, and away from consensus influence while also continually seducing a problematic user to “redeem” their conversation.
We call these events Fault and Spin–movements of conversation where problematic thinking or participation is encountered.
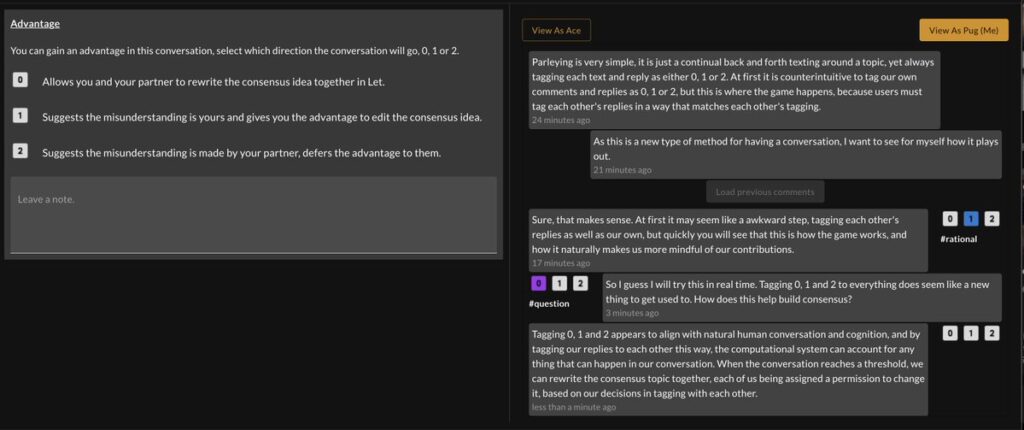
Advantage and Let
Once the threshold is reached, participants co-write what is reliable and “true”, what is personal or what the misconception is about, and what is the open question around the topic, winning these permissions through the game play, which publishes the outcome in a transparent way. We call this “contextual completeness”, understanding the spectrum of what is true, what is misunderstanding, and what is an open question around any topic idea.
No voting or popular opinion is required, just thorough deliberation.
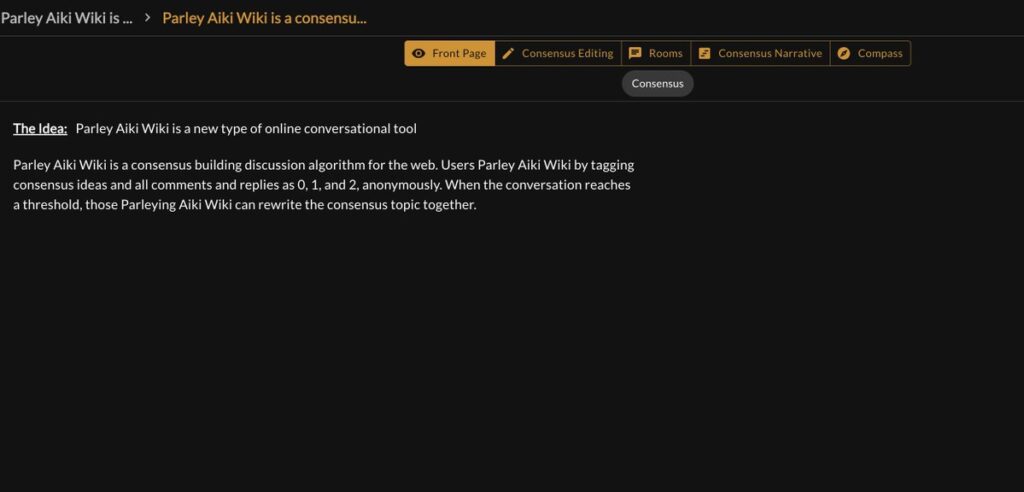
This is how the Consensus idea started, a single coherent idea…but the idea can change…
Open Championship
This is the result, one single coherent idea was transformed into an article with “contextual completeness”, or the “total view”, what is known, personal, and what is unknown in the topic, published as an article through conversation, computationally.
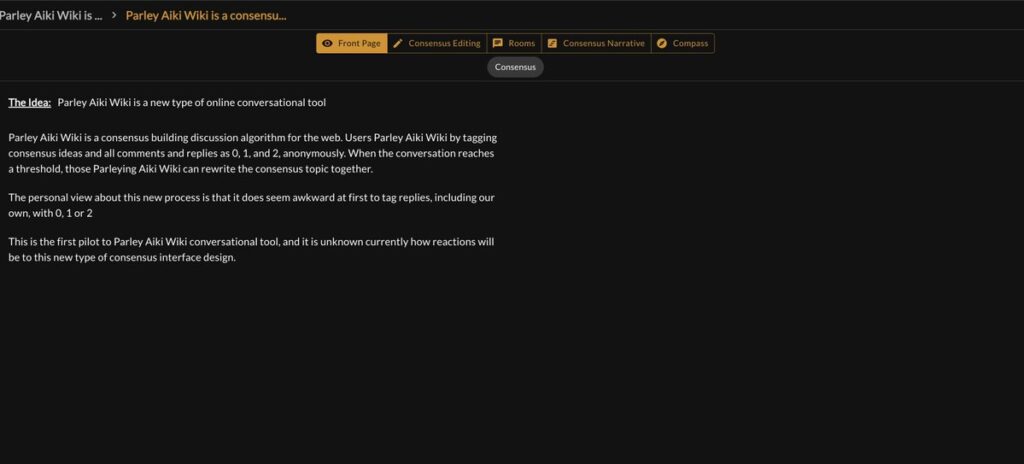
We call this “Open Championship” because the in the full system of Aiki Wiki, the topic remains open for others to improve or refine the analysis, going through the same arcs of Parley Aiki Wiki as the first paired couple.
Convergence or Abandonment
At each moment of game play, decision making incentivizes convergence, or a mutual agreeable outcome in some way, while abandonment, deception or trolling has neutral effect on the outcome of the consensus process.
The Narrative View of the Consensus.
The Narrative View is able to computationally “tell a story” about all events, conversations, and decisions in the system.
For our pilot, our narrative view is in quite a crude form and more of a placeholder in the system for now, a sort of narrative “time stamping”.
But as we evolve The Narrative View, especially when we add AI, the Narrative View will become quite a robust and transparent reliable third party report of everything that happens in a consensus process.
This means the system can account for all possible outcomes within a challenged conversation between conflict and resolution, and deliver a reliable third party narrative about what happens in a large group consensus where everyone is anonymous.
The system itself refrains from any decision making, the system never “chooses” or makes any selection autonomously––rather it is simply the inputs from those participating, the tagging of 0, 1 and 2, that determines all publications and rankings in the system.
What happens when?
Parley represents single paired conversations, which we will scale in the next milestone phase, with our first milestone capturing an entire consensus topic, comprised of single coherent consensus ideas, to be discussed, deliberated, and co-written by up to one hundred people.
At this point we predict emergent abilities to create the following circumstance:
One hundred people would be paired into fifty conversations to begin, fifty one-on-one conversations, each initiating on a single consensus idea.
If two individuals who disagree on a single topic happen to be individuals who are more naturally collaborative and rational, we can predict that they will be awarded editing permissions on every single topic if these two individuals are paired, despite disagreement.
If two individuals are paired have a tendency to both be competitive, irrational, engage in argument that is comprised of being some sort of an a**hole, perhaps liars or cheats of some kind––then the system should keep them away from consensus influence, unless they adopt the dominant strategy.
We can predict that these individuals are more likely to abandon than converge, but either way they can continue their discussions. However, we can implement the isolation of conversation that becomes toxic. So the platform does not need to “censor” the worst of views, merely isolate them, away from influence.
But what happens if the pair is comprised of one single naturally rational and collaborative psychology with a psychology that is competitive, potentially even a jerk?
The “jerk” can redeem their “win or lose” mentality and adopt the dominant strategy of the system, win win consensus editing, or they can abandon.
Scaled psychological blockchain
We can predict under such conditions that in consensus between groups of ideological divides, the more rational and collaborative psychologies of each side of one ideological divide will eventually find each other in the consensus process and those most inclined to collaboration and rational thinking will influence the outcome of the consensus.
Additionally in the next milestone phase, we can predict that any ideological divide that carries influence from what is known as “group think” will collapse under these conditions.
Please support the Win Win Protocol for the World Wide Web
This project could use some help and support. While its opportunities are boundless, we want to “move quickly and fix things” and are currently cultivating team building, partners, and fundraising.
We are currently raising funds to further develop Aiki Wiki, set up the companies and global library, as well as resubmit for the National Science Foundation’s SBIR program, which invited us to submit the project.
If you would like to send crypto support for the project to help keep development going, please do 🙂
Ethereum and Matic: 0xaaA8503B7281e50Cc2bFa08ff328d6A54057101e
Bitcoin: bc1pc3s8f9f7c0xwkfm2wrpg54wlehen990gyx9tnng4ydq64tqmukgscw9svx
If you would like to support Aiki Wiki through BAE or private investment, reach out to rome at bigmotherdao DOTCOM.